
Out of scale: why blockchains don’t deliver
#2 in our series “Off the chain”

What follows is an introduction, not a full technical treatment. To keep the narrative clear, some explanations are simplified or generalised, and edge cases are set aside. The goal is to give a first map of the scaling challenges in decentralised networks without burying the reader in detail.
In the previous article, we saw how blockchain — and DLT more broadly — was introduced as a kind of digital trust machine, meaning a system that can guarantee the integrity of data without leaning on any central authority. By moving the burden of trust from institutions to code, it provides a foundation on which strangers can cooperate safely, without needing to place faith in one another, or, for that matter, in middlemen.
On paper, this would seem like the ideal basis for open and user-empowered economies. But for many, the first encounter with decentralised networks has been less empowering than confusing, with obscure jargon, complex key management, high gas fees, and pending or failed transactions. Instead of lowering barriers to entry, the technology has often raised them, frustrating newcomers and leaving them feeling more excluded than empowered.
While some of these frictions have eased with more polished and well-designed applications, deeper problems remain. And so, the very infrastructure remains burdened with architectural limitations: many networks are slow and expensive to use, and difficult to upgrade, making long-term innovation a frustrating game of patchwork fixes. In light of this, creating an app with a nice interface seems a bit like adding a high-tech infotainment system to a carburetor-driven car. Sure, it will make the car look nice and modern, but it won’t make it drive any better.
What holds DLT back, then, isn’t the dashboard, but the engine. And the engine suffers from a scaling problem. To understand what this means, we need to lift the hood and look at the core machinery that makes decentralised networks run. Here we find that decentralised systems are powered by three tightly linked components (in this context, often referred to as layers), each of which must scale if the whole engine is to perform:
- Consensus, which is the process of agreeing on the order of transactions and the state of the ledger
- Execution, which is the process of verifying and applying those transactions to the ledger
- Storage, which is the process of maintaining both the transaction history and the resulting state of the ledger
In what follows, each of these will be explored in depth, and it will be shown that attempts to scale any one layer almost always come at the cost of compromising decentralisation.
But we will also look beyond consensus, execution, and storage. After all, the scaling problem is not limited to these layers alone. It also grows out of the way many networks have been designed. Certain choices, most notably the monolithic architecture of some networks and their reliance on stateful smart contracts, bring bottlenecks of their own. These, too, will be covered in this article. Before getting there, however, we need to clarify what we mean by scalability. So that’s where we begin.
The Price of Going Faster
When talking about scalability, we refer to a network’s ability to handle more users, more versatile use cases, and more transactions (a transaction here means a unit of change to the ledger: add, edit, or delete). And this is precisely what decentralised networks need if they are to move beyond supporting niche use cases and serve as the foundation for open, large-scale digital economies.
Unfortunately, achieving scalability is anything but easy. Because if you want a decentralised network to handle more users and process transactions faster, you often have to either weaken its security guarantees or concentrate control in fewer hands. This problem has been famously formalised as the DLT trilemma: you can optimise for scalability, security, or decentralisation, but only two at once.
In practice, though, this trilemma rarely appears as a three-way choice. More often, it plays out as a trade-off between scalability and decentralisation. Partly this is because security and decentralisation tend to move in tandem: a more decentralised system is harder to seize control of or censor, and therefore more secure. But it’s also because no serious project is willing to openly compromise on security, as it would undermine the very purpose of its existence. Consider, for instance, what it would mean for a network to lack strong security: funds could be stolen, contracts manipulated, and the system itself rendered unreliable. That’s hardly the kind of network you would trust with your savings. Or your data.
What remains, then, is a tug-of-war between scalability and decentralisation, where greater speed and throughput typically come at the cost of concentrating power in fewer hands. And conversely, greater decentralisation tends to slow the system down and reduce its capacity to scale. For most DLTs, then, the remaining di-lemma ultimately takes the form of a choice: how much decentralisation are we willing to sacrifice to gain scalability? Or how much scalability are we prepared to forgo in order to preserve decentralisation?
For early DLTs, the answer was obvious: decentralisation came first, even if it meant living with painfully low throughput and high transaction costs. But many newer networks have flipped that equation, chasing performance by centralising the system, thus giving greater control to a smaller group. The trade-off is often justified as a temporary measure (“we’ll decentralise later”), but in practice, centralised structures have a way of becoming permanent.
Of course, the conversation isn’t as simple as scalability versus decentralisation. While decentralised networks must indeed balance competing priorities, these priorities are not static measures that can be precisely defined. Yet, discussions around decentralised networks often reduce them to just that, that is, checkboxes to be ticked off, as if a network is either decentralised or it isn’t, scalable or it isn’t. As obvious as it may seem, these are relative measures that exist on a spectrum. Therefore, when we talk about networks sacrificing decentralisation for scalability, or vice versa, we are not saying they flip from one extreme to the other. Instead, they are shifting along a spectrum, trading a little of one to gain more of the other. But every shift has consequences. A network that scales by centralising risks losing some of the qualities that made it valuable in the first place. And that’s exactly where a lot of decentralised networks find themselves today: gaining speed but losing decentralisation.
Still, most users may not care how decentralised a network is, as long as their transactions are fast, cheap, and secure. And in the short term, that’s a reasonable trade-off. But it’s worth remembering that decentralisation and security often go hand in hand: systems that concentrate control increase the risk of censorship, collusion, or outright capture. Just consider a Brazilian company, whose entire supply chain runs on a decentralised network operated by a closed network of computers, the majority of whom are run by entities legally exposed to U.S. regulatory frameworks. If the U.S. were to impose sanctions on Brazil, this network of computers, whether by legal obligation or political pressure, could be forced to deny the company access altogether, in which case, the lack of decentralisation becomes a systemic vulnerability that exposes the network and its users to external interference.
But capture can also come from the inside. When the network is concentrated in the hands of a small circle of people or entities, decisions about upgrades, fees, and policy are more likely to serve those insiders rather than the wider community of users. In that case, the risk is not censorship from the outside, but a gradual shift toward a network that primarily benefits its own operators.
Whether pressures from without or temptations from within, decentralisation, then, is what makes these systems open, resilient, and resistant to centralised control, and that’s precisely what we are at risk of losing when performance becomes the primary goal.
So, at the end of the day, the problem looks like this: every gain in speed risks narrowing participation, while every push for broader participation risks slowing the system down. To really understand why this is, we need to start by considering what it means for a network to be decentralised.
Consensus: Do We All Agree?
When we want to scale traditional databases, the usual playbook is to add more machines (horizontal scaling) or make existing ones faster (vertical scaling). As such, making it faster is mostly a matter of throwing resources at it. Decentralised systems, however, don’t have that luxury. To see why this is, it’s worth stepping back to consider what it means for a system to be decentralised in the first place.
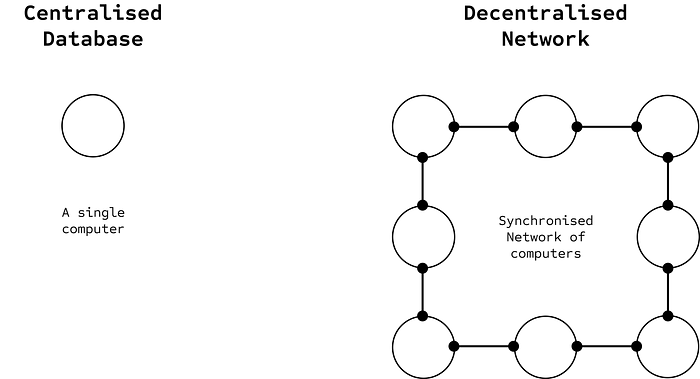
A distributed system is a network made up of many machines that work together as if they were a single computer. A decentralised network is a special type of distributed system where the machines — or nodes — are run by independent people or organisations who do not have to trust each other. What ties these nodes together is a shared state: a common view of the system’s data, rules, and operations that must remain consistent across all participants. In blockchains, this state is derived from a common transaction log known as the ledger. Each node maintains its own copy of the ledger and computes the state from it, and those copies must stay in sync as new transactions are added. To make this possible, the nodes must agree on the order of transactions — and therefore on the resulting state. This process is called consensus. And reaching it in a decentralised environment is anything but simple.
Unlike tightly controlled databases, decentralised networks must assume that not all nodes can be trusted. Some might crash or go offline, and others might act maliciously, whether out of self-interest or sabotage, for instance by sending misleading or invalid messages to other nodes. And yet, the system must persist, reaching consensus and progressing forward even in the presence of faulty actors. This is what is known as Byzantine Fault Tolerance, or simply BFT.
BFT describes a decentralised network’s ability to operate correctly even when a portion of its nodes do not respond or behave dishonestly. In practical terms, BFT ensures two critical properties: that the network continues to make progress (liveness), and that the nodes of the network agree on a single, shared state (safety).
Now, traditional BFT protocols like Practical Byzantine Fault Tolerance (PBFT) rely on all-to-all communication, meaning the number of messages grows quadratically with the number of nodes. Here, consensus requires multiple rounds of back-and-forth communication, a process that quickly becomes unmanageable as the number of nodes grows. Therefore, keeping all nodes in sync often means capping the number of participating computers.
Blockchains like Ethereum, on the other hand, ease these constraints and enable broader participation. They do so by simplifying the consensus process: instead of all-to-all communication, a selected block proposer — commonly referred to as the leader — assembles transactions into a block and broadcasts it to the other nodes.
But simply having the leader broadcast a block is not enough. Other nodes may not accept it, let alone receive it, so there needs to be a way to know whether the network as a whole agrees on what has happened. Therefore, nodes must have a mechanism to signal that they have accepted the block and updated their own ledgers. In Ethereum, validators publish attestations to show they consider the block valid, and these attestations are efficiently aggregated and shared so the whole network sees the result without everyone having to talk to everyone else. Thus, network-wide agreement on a block is achieved without the need for burdensome communication between nodes.

Ethereum thus minimise communication overhead, which enable it to function with many more nodes, but it does so by concentrating responsibility in a single node. However, when the network hinges on a single node acting as leader, and that leader is publicly known, a well-placed denial-of-service (DoS) attack need not target the entire network, but only the block leader to bring it temporarily to a halt. Moreover, centralising block production opens the door to transaction-ordering manipulation, allowing the leader to reorder transactions for profit. And so, the very optimisations designed to make BFT — and consensus — more efficient, become the vectors that make it more brittle.
But since our focus is on the trade-offs between scalability and decentralisation, that’s somewhat beside the point. What matters here is that concentrating responsibility in a single proposer creates a bottleneck that limits throughput. When only one node is responsible for creating a block at a time, the overall speed of the network is constrained by that node’s ability to process and disseminate this block. And so, each block must wait for the previous one to be propagated, validated, and finalised before the next can be produced.
Speeding up block production might seem like a good solution, but it introduces the risk of so-called forks, where nodes disagree on the current state of the ledger. This happens when a new block is produced before the previous one has had time to propagate across the network. As a result, different nodes may begin building on different histories, leading to temporary chain splits. For users, this means that transactions that appear confirmed might later be reversed when the fork is resolved, a process known as a reorg.
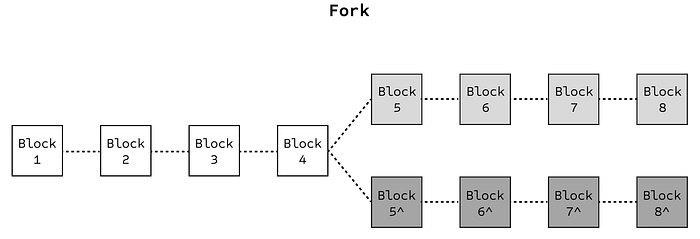
To mitigate the risk of forks, Ethereum therefore maintain relatively long block intervals, giving time for blocks to reach consensus across the global node set, but at the cost of slower transaction throughput. In other words, the very need to maintain consensus across a decentralised network of computers constrains the system’s ability to scale.
Execution: The Weakest Link
As we have seen so far, the very process of reaching consensus imposes inherent limits on the ability of decentralised networks to scale. But rather than accept these limits, blockchain architects have searched for ways around them. One promising solution has been to scale the execution layer.
Execution, simply put, refers to the act of processing transactions. It is one continuous process, but we can think of it as having two sides: first, there is the act of verifying that transactions are valid in the proposed order, and second, there is the act of applying them to the ledger.
Now, in a decentralised network, execution is repeated independently by every node. The reason is simple: in a decentralised system, no single party is trusted to process transactions on behalf of everyone else. Each node must be able to verify the transactions, whether that means checking a signature, confirming a balance, or running a smart contract according to the rules, before updating its own copy of the ledger. If each node didn’t do that, the system would have to fall back on trusting a central authority, leaving it vulnerable to errors or fraud, the very problems decentralisation is meant to avoid.
From the perspective of security, this is great: even if some nodes act dishonestly, the rest can confirm the correct state without relying on them. But from the perspective of scalability, it is an inefficiency: the network’s effective throughput is limited by the computing power of the weakest nodes. Why is that?
Recall that consensus requires the nodes to remain in sync. This does not just mean receiving the latest block from the leader, it also means executing it. Each node must verify that every transaction in the block is valid, by confirming signatures, balances, and contract logic, and then apply those transactions to its local copy of the ledger. Only by doing so can all honest nodes arrive at the same state and maintain a consistent view of the system.
If some nodes fall behind in this process, they are unable to validate new blocks in time, which raises the risk of forks. For instance, if one computer cannot process transactions as fast as blocks are produced, it may lag behind the rest of the network. It may even miss some blocks altogether. This means that its local record diverges from that of others and that competing versions of the ledger will emerge.
To avoid this, block production must slow down to a pace that even the weakest participants can reliably keep up with. In effect, the throughput of the entire network is constrained by the speed of its slowest ones. The (block)chain, quite literally, is no stronger than its weakest link.
The “weakest link” analogy, however, should be taken with some caution. Consensus does not require every single node to keep pace: a minority may fall behind without threatening the system, provided that a supermajority remains in sync. Even so, in leader-based protocols the analogy proves accurate: if the leader cannot keep up, the entire network is held back. In that sense, the chain is only as strong as its weakest leader.
Yet, newer networks do seem to manoeuvre around this problem. Networks like Solana and Sui, for example, reduce block times dramatically and, in doing so, achieve thousands of transactions per second. How is this possible? By requiring validators to run on powerful machines and keeping the set of participants tightly managed, they ensure all nodes can keep up with the execution process. Put differently, there are no weak links and no weak leaders. By narrowing the set of validators to those with powerful machines and fast connections, these networks can produce blocks at a high pace and do so with minimal risk of forks (This is only half the truth: they also rely on a form of stateless smart contracts, which allow transactions to be processed in parallel. We will set that aside for now and return to it in later blog posts, so as not to complicate things.)
So yes, they are faster, but at what cost? The challenge is not just building a network that runs at breakneck speed, but creating one that scales without cutting corners on decentralisation. And that’s a much harder problem to solve.
We also see this tension in the attempt to scale older networks, such as Ethereum. Their solution has been to optimise execution through so-called Layer 2s (abbreviated as L2s), which are satellite networks that orbit the Ethereum network, known as the Layer 1 (abbreviated as L1). These L2s are used for executing transactions off the main network (off-chain) and periodically send back a summary for final recording on the L1. Said differently, the L2 execute hundreds or thousands of transactions, compresses them into a batch, and posts that batch to the L1 inside a single L1 transaction. By doing so, L2s speed up execution and reduce fees, offering a much-needed performance boost to the L1.
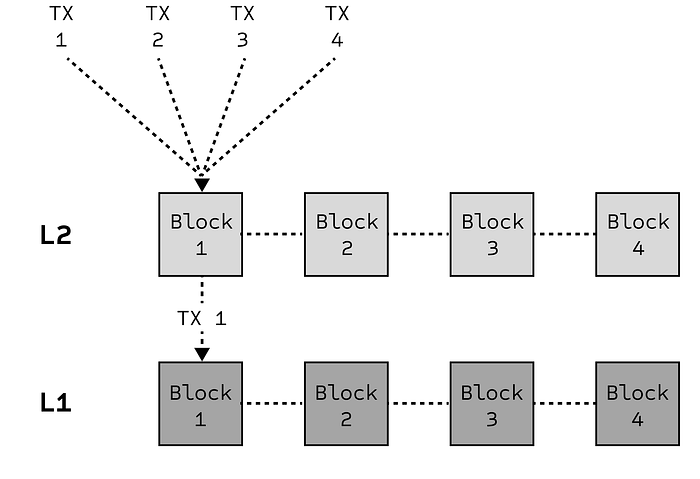
But while L2s may help scale execution, they’re no silver bullet. Many rely on centralised sequencers, that is, entities that control the order in which transactions are processed. This introduces a new set of risks: sequencers can delay, reorder, or censor transactions, undermining the very decentralisation the L1s aim to preserve. Moreover, because these networks rely on a single sequencer, they forfeit BFT, leaving them unable to keep the network responsive and resilient in the face of faults or malicious behaviour. These risks, to be clear, are not purely theoretical. L2 networks like Arbitrum and Optimism have previously experienced sequencer outages, leaving users temporarily unable to transact.
Even scalability, the core promise of L2s, is not guaranteed. On Ethereum, L2s depend on something called ‘blob space’ to post their transaction data back to the main chain. You can think of blobs as lightweight containers that carry compressed summaries of off-chain activity and make it cheaper and faster to store this information on the L1, while still allowing anyone to verify that the transactions are valid. The problem, however, is that blob space is finite. With only a handful of slots available per block and an ever-growing number of L2s competing for them, congestion is inevitable. Thus, in trying to scale Ethereum, L2s have ended up in a scalability problem of their own, solving one bottleneck only to create another.
Storage: The Weight of History
So far, we have seen that scaling a decentralised network is inherently problematic, since doing so almost always means compromising on its decentralisation, a problem that shows up clearly in both consensus and execution. But the story doesn’t end there. The same tension also appears in storage, which introduces its own version of the scalability trade-off.
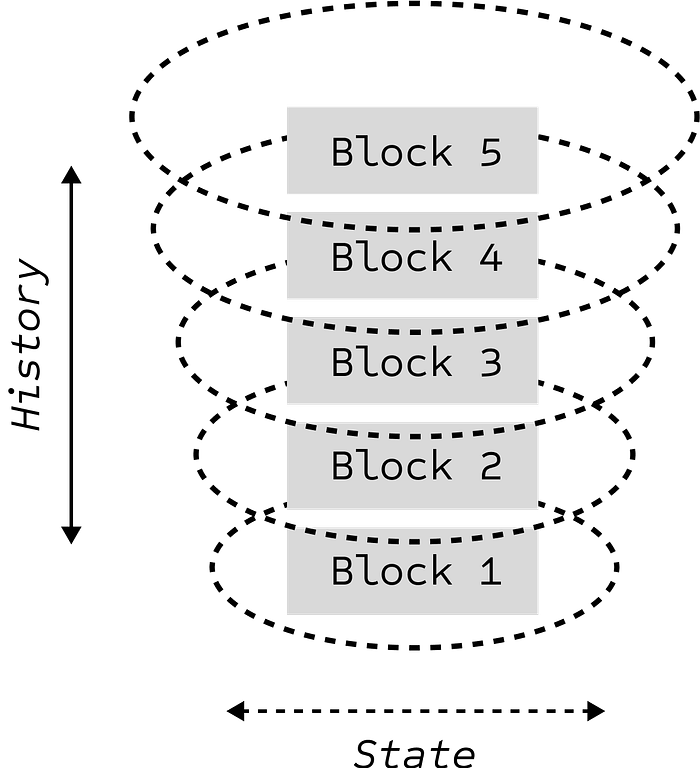
In the context of decentralised networks, storage refers to the responsibility the nodes bear for maintaining the ledger: not just the historical record of all past transactions, but also the current state that results from them.
Both of these grow persistently. The historical record expands with every block added, and because transactions are never deleted, the total history only increases over time. Meanwhile, the current state grows with network activity: every new account and every deployed contract leaves behind data that must be preserved and updated. The result is a ledger that swells in two directions at once: upward through the accumulation of history, and outward through the expanding live state of the ledger.
Now, it makes sense that nodes need to keep the current state of the ledger. After all, without it they couldn’t verify whether new transactions are valid. For instance, if I were to send you one USDC (a dollar stablecoin), every node would need to check that my account actually holds at least that amount, that my signature matches, and that the transfer obeys the protocol’s rules. Without the current state, none of this could be confirmed.
But why do they need to keep the full history? The reason is verifiability. A decentralised network can only claim to be trustless (meaning users can verify everything themselves rather than relying on others) if anyone, at any time, can start from the beginning and independently check that the current state really is the product of a valid sequence of transactions. The history is the audit trail: it proves that balances and contracts didn’t just appear out of thin air but were built step by step according to the rules. For example, suppose you join the network today and want to be sure that my account really does hold the one USDC I just sent you. You don’t have to take anyone’s word for it. Instead, you can download the entire transaction history from the very first block. Starting with an empty ledger, you replay every transaction in order and update the state step by step. By the time you reach the latest block, the balance in my account will show exactly what the network claims it does.
So, both the history of transactions and the current state are needed. But not every computer has to store everything. Decentralised networks allow different kinds of nodes to store different parts. For instance, validators, which take part in consensus, can delete old transaction data, keeping only the live state and a compact record of each block. An archive node, on the other hand, keeps absolutely everything, including the full record of past blocks and the exact state at every point in time.
This division of labour helps reduce the burden on individual machines, but it doesn’t remove it. For instance, every validator must keep the live state up to date, and this puts real limits on the kinds of computers that can join consensus. As the network scales, the state grows with every new account, contract, and piece of on-chain data. Storing and updating that larger state requires more disk space (bytes) and enough memory (RAM) to handle it smoothly. As the state swells, the bar for running a validator therefore rises, leaving fewer computers able to keep up.
The same applies to storing the transaction history: The inexorable growth of historical records poses a risk to decentralisation. If the ledger history balloons to hundreds of gigabytes — or terabytes — only well-resourced operators with ample disk space can afford to maintain full archives. As the number of archive nodes shrinks, new participants can no longer reliably bootstrap from a wide set of independent sources. Instead, they are forced to trust a small group of archive providers to supply historical data or verified snapshots.
This creates two problems. First, it introduces soft trust into a system that is supposed to be trustless: if only a handful of operators store history, the rest of the network must take their word that the data has not been altered. Second, it creates chokepoints. A thinner set of archive nodes means fewer independent checks, more chokepoints for censorship or data withholding, and a greater reliance on large, centralised infrastructure providers.
Once again, the iron law of scaling a decentralised network applies: scalability comes at the expense of decentralisation.
Design Choices and Hidden Costs
So far, we have covered the core dilemma of scaling a decentralised network: the tug-of-war between scalability and decentralisation, and how it plays out in consensus, execution, and storage. There are, however, other dimensions to the scalability problem that are different in kind. These do not arise from the intrinsic trade-off of “faster networks mean fewer participants”, but from architectural choices. Chief among these are the monolithic structure of most DLTs and the reliance on stateful smart contracts. We will turn to these now, starting with the former.
Monoliths Don’t Age Gracefully
Most decentralised networks are monolithic. In a monolithic network, ordering transactions, executing them, and storing the resulting state, all happens inside one tightly coupled protocol. Over time this has become a constraint, because when everything is bound together, touching one part affects the rest: a tweak to execution or consensus can force changes elsewhere, and even small upgrades require network wide coordination and careful testing across the whole stack. The result is a slower pace of innovation and an ever-growing burden on those tasked with maintaining the network. Each new upgrade demands more effort, more coordination, and more risk. Over time, this slows innovation and makes it harder for the network to adapt to new use cases, shifting demands, or unforeseen challenges.
Ethereum is a case in point. Every upgrade, from EIP-1559 to The Merge, has introduced new functionality, but also new technical debt, as core developer Péter Szilágyi has pointed out. And so, while these changes have pushed the network forward, they have also made it harder to navigate, maintain, and innovate upon. Complexity, in other words, compounds.
Today, some of this complexity is being pushed outward. As noted earlier, Ethereum now relies on L2s to handle most execution, leaving the base layer to focus on consensus, security and on storing the data needed to verify what L2s do (often called data availability). This modular turn is what allows innovation to continue without rewriting the core protocol at every step.
These off-chain environments offer speed and flexibility, helping applications sidestep the constraints of a monolithic architecture. But they do so by fragmenting the ecosystem. Each L2 operates in its own silo, with separate state, liquidity, and security assumptions, none of which are natively interoperable. The result are networks that scale outward, but lose coherence.
The economic arrangement is similarly imbalanced. L2s benefit from Ethereum’s security guarantees, anchoring their trust in the mainnet’s validator set, yet contribute little back to its upkeep. Said differently, security is maintained by one set of actors (the validator nodes of the L1), while value creation shifts to another (the operators of the L2). What emerges are parasitic L2s, where throughput improves by extracting resources from the base layers without adequately reinforcing them.
A scalable network, therefore, is not just one that processes more transactions, but one that seamlessly scales to meet the demands of its users without compounding internal complexity or splinter into isolated siloes.
Smart Contracts
There is one final side to the scalability problem that deserves attention: the use of stateful smart contracts. These contracts sit at the heart of many decentralised networks, powering lending markets, exchanges, games, and much more. They give developers the tools to build rich applications and users the ability to interact with them directly on-chain. Yet, the very feature that makes them so powerful also creates a limit on scalability, placing a ceiling on how much throughput the network can handle. And this is where we finally turn our attention, in what has by now become quite a long journey through the scalability problem.
As a first step in this endeavour, we start by asking: what is a smart contract? The concept was introduced in the mid-1990s by Nick Szabo, years before blockchains existed. In his words, a smart contract is “a set of promises, specified in digital form, including protocols within which the parties perform on these promises”. In everyday terms, it is just code that takes an input and automatically applies a set of agreed rules so that the outcome of happens without a middleman. Szabo’s favourite analogy was the vending machine: put in the right coins and press a button, and you will always get the drink you selected.
On a smart contract-powered blockchain the same principle applies. When you send the right input, the contract executes its rules automatically and records the result on the ledger for everyone to see. Using the example from our first blog post, suppose you want to trade money for an asset. You do not hand over your money first and simply trust the other party to follow through. Instead, a smart contract ensures that both sides of the exchange happen together or not at all: Either you get the assets at the same moment you give up your money, or the whole transaction fails and nothing changes. Like a vending machine. This all-or-nothing property is what makes such trades atomic, and it is one of the ways smart contracts remove the need for trust in digital transactions.
So now we know what a smart contract is. But what does it mean for one to be stateful? Put simply, it means the contract has a state, that is, persistent data that it carries across interactions. In practice, this state lives on-chain as part of the shared state every node maintains. Instead of carrying out a task and then forgetting it, the contract loads its previous state from the blockchain, updates that record, and carries it forward to the next interaction. So, for instance, if you deposit funds into a lending pool, the contract remembers your balance. When you borrow against it, the contract checks that record to make sure you have enough collateral. When you repay the loan, it updates the balance again.
This memory is what turns blockchains from simple payment rails into platforms for full-fledged applications. But it also comes with a catch. Because each new transaction depends on the state left behind by the one before it, contracts cannot simply process everything in parallel. They must be handled in sequence, step by step, so that each update to the state happens in the right order. Imagine thousands of people trying to edit the same spreadsheet at once: if two people change the same cell at the same time, which version is correct? The network resolves this by processing transactions one after another, but that limits throughput.
This also means that simply giving nodes more powerful hardware does not allow the network to run faster. A faster processor might speed up each individual step, but it cannot change the fact that the steps have to happen one after another. As long as contracts depend on a shared memory that must be updated in the right sequence, the system cannot process transactions in parallel and thus increase throughput. In other words, throughput is capped not only by hardware, but by the logic of stateful smart contracts themselves.
Conclusion
We set out to understand why decentralised networks struggle to scale. The short version is this: scaling a decentralised network is not just a matter of bigger servers, but about keeping many independent parties in sync, all while protecting the openness, neutrality, and security that make these systems worth using in the first place.
At the core of this scaling problem sit three tightly linked parts:
- Consensus, which must keep many computers in sync, which sets natural speed limits.
- Execution, which must be repeated by many nodes, so the network moves at the pace of its slowest participants.
- Storage, which must carry both the full history and the live state, which raises the bar for who can meaningfully take part in the network.
As we have learned, scaling any one of these layers usually comes at the expense of decentralisation. And weakening decentralisation makes the network more susceptible to both external and internal control.
On top of these built in limits come design choices. Monolithic architectures, prevalent in most DLTs, bundle consensus, execution, and storage into one shared protocol. This causes complexity to pile up, making upgrading the network slow and difficult. And stateful smart contracts, which give us powerful applications, means transactions must be processed sequentially.
So, what does scalability actually look like? It’s about handling the needs of users, without giving up on decentralisation. In our next article, we will explore how Tagion takes on this challenge, offering both scale and decentralisation.
Listen To The Article

Founder & CEO Osiz Technologies
Mr.Thangapandi, the founder and CEO of Osiz, is a pioneering figure in the field of blockchain technology. His deep understanding of both blockchain technology and user experience has led to the creation of innovative and successful blockchain solutions for businesses and startups, solidifying Osiz's reputation as a reliable service provider in the industry. Because of his unwavering quest for innovation, Mr.Thanga Pandi is well-positioned to be a thought leader and early adopter in the rapidly changing blockchain space. He keeps Osiz at the forefront of this exciting industry with his forward-thinking approach.



No 22,Astalakshmi Nagar, Thanakankullam, (Opp Seetha lakshmi Mill gate Bus stop) Thirunagar, Madurai - 625 006.
(Corporate Office)


10466 Shire View Dr, Frisco, Texas 75035, United States of America USA.
(Sales Office)


Canada Office address, 1150, Rue Patrick, Laval, Quebec - H7Y 2C4, Canada.
(Sales Office)

Black Friday 30%
Offer
- Explore AI
 Artificial Intelligence
Artificial Intelligence- AI Development
- AI as a Service
- Data and Analytics Services
- Machine Learning Development
- Enterprise AI Solution
- AI Consutling Services
- AI Integration Services
- AI Agent Development
- AI Assistant Development
- Hire AI Engineers
- Hire Prompt Engineers
- Hire Chatgpt Developers
- Hire Stable Diffusion Developers
- Hire Action Transformer Developers
- AI Chatbot Development
- Transformer Model Development
- AI Co-Pilot Development
- Adaptive AI Development
- Chatgpt Development
- Large Language Model Development
- NLP
- AI Brainstorming
- AI Consulting and Idealogy Development
Blockchain- Blockchain Development
- Smart Contract Development
- Custom Blockchain Development
- Solana Blockchain Development
- Polygon Blockchain Development
- Public Blockchain Development
- DAO Blockchain Development
- Binance Smart Chain (BSC) Blockchain Development
- DApp Development
- Solana DApp Development
- White Label Blockchain Solutions
- Custom Blockchain On Avalanche
- Custom Blockchain On Polygon
- Blockchain Game Development
- Blockchain Consulting Services
- Blockchain Explorer Development
- Proof Of Reserve
Layer 1 & 2 Solutions- Layer-1 Blockchain Development
- Cross Chain Bridge Development
- Data Availability Layer Development
- Ethereum Layer 2 Scaling Solutions
- Cross-L2 DEX Solution
- Layer 2 Token Development
- Layer 2 Token Marketing
- Layer 2 Cryptocurrency Development
- Layer 2 Solutions For Blockchain Games
- Layer 2 Solutions For Web3 Gaming
- Layer 2 Blockchain Solutions
- Rollups As A Service
- Optimistic Rollups Development
- ZK Tech Development
- Bitcoin Layer 2 Solutions
CryptoCrypto Exchange- Cryptocurrency Exchange Development
- White Label Crypto Exchange
- Decentralized Exchange Development
- P2P Exchange Development
- Crypto Derivatives Exchange Development
- Centralized Exchange Development
- Crypto Exchange Clone Script
- Cryptocurrency Exchange App Development
- OTC Exchange Development
- Exchange Listing Services
- Binance Like Exchange Development
- Bitstamp Like Exchange Development
- Crypto Exchange Script
Crypto WalletToken Standards- Token Development
- AI Token Development
- Asset Tokenization
- Real Estate Tokenization
- Tokenization Platform Development
- Crypto ETF Development
- Solona Token Development
- Semi-Fungible Token Development
- BEP20 Token Development
- Ethereum Token Development
- ERC1400 Token Development
- ERC998 Token Development
- ERC 721 Token Development
- ERC20 Token Development
- Defi Token Development
- ERC1155 Token Development
- BEP721 Token Development
- Utility Token Development
- ERC 777 Token Development
- ERC 827 Token Development
- Social Token Development
- Metaverse Token Development
- Tron Token Development
- ERC404 Token Development
- Governance Token
- Shibarium Token
- polygon Token
- BRC-20
- TRC20 Token Development
- TRC10 Token Development
- Soulbound Token Development
- NFT Token Development
Trading BotsClone- Crypto Exchange Clone Script
- Binance Clone Script
- Coinbase Clone Script
- Kucoin Clone Script
- Paxful Clone Script
- Remitano Clone Script
- Wazirx Clone Script
- ByBit Clone Script
- Bitfinex Clone Script
- MEXC Clone Script
- Bitget Clone Script
- Cointool App Clone Script
- Trust Wallet Clone App
- Coinmarketcap Clone Script
- Changelly Clone Script
- BingX Clone Script
CybersecurityApp SecurityDigital Forensics & Incident ResponseAudit & ConsultingEducation & TrainingSolutionsWeb 3DeFi- Decentralized Finance (DeFi) Development
- DeFi Lending/ Borrowing Platform Development
- DeFi Staking Platform Development
- DeFi Token Development
- DeFi Wallet Development
- DeFi Smart Contract Development
- DeFi DApp Development
- Decentralized Exchange Development
- DeFi Insurance Development
- DeFi Crypto Synthetic Assets Development
Game Development- Game Development
- Android Game Development
- IOS Game Development
- Metaverse Game Development
- VR Game Development
- AI Game Development
- Unity 3D Game Development
- Unreal Engine Game Development
- Mobile Game Development
- Blockchain Game Development
- NFT Game Development
- Play to Earn Game Development
- Move to Earn Game Development
- Casino Game Development
- Slot Game Development
- Poker Game Development
- AAA Game Development
- AR Game Development
- Social Network Game Development
- Gamification Services
- Decentralized Sports Betting Platform
- Sports Betting Dapp Development
- Blockchain Casino Game Development
- Game Asset Creation
- Baccarat Game Development
- Rollbit Clone Script
- Fortnite Clone Script
- Slot Game Development
- Tap to Earn Game Development
- Slot Game Development
Metaverse Platforms- Metaverse Game Development
- Metaverse Event Platform Development
- Metaverse Virtual Mall Development
- Metaverse NFT Marketplace Development
- Metaverse Token Development
- Metaverse Virtual Land Development
- Metaverse Avatar Development
- Metaverse 3d Space Development
- Metaverse Real Estate Development
- Metaverse Social Media Platform Development
- Top 10 Metaverse Development Company
- Metaverse Business Ideas
- Metaverse Launchpad Development
- Metaverse App Development
- Metaverse Casino Game Development
NFT SolutionsNFT Platforms- NFT Minting Development
- NFT Exchange Platform Development
- NFT Launchpad Development
- NFT Fashion Marketplace Development
- NFT Art Marketplace Development
- NFT Music Marketplace Development
- Carbon Credits NFT Marketplace Development
- Binance NFT Marketplace Development
- Polygon NFT Marketplace Development
- Solana NFT Marketplace Development
- Influencers NFT Marketplace Development
- NFT Ticketing Marketplace Development
- DeFi NFT Marketplace Development
- NFT Fantasy Sports Platform Development
- NFT Storage Development
- NFT Lending Platform Development
- Top10 NFT Business Ideas
NFT Game ClonesSustainabilityServiceNow- Blog
- Contact Us
- Works
- Dataset